DeepSeek-R1's Sub-$6 Million Development Highlights Reinforcement Learning's Cost-Effective Power in Advanced AI Reasoning
A newly published comprehensive survey, "A Survey of Reinforcement Learning for Large Reasoning Models," underscores the critical and evolving role of Reinforcement Learning (RL) in transforming Large Language Models (LLMs) into highly capable Large Reasoning Models (LRMs). The paper, recently highlighted by prominent AI engineer Rohan Paul, positions RL as a foundational methodology driving significant advancements in AI's ability to tackle complex logical tasks.
The survey, authored by a collective of 39 researchers including Kaiyan Zhang and Yuxin Zuo, details how RL has achieved "remarkable success" in enhancing LLM capabilities, particularly in areas like mathematics and coding. It emphasizes the timely need to reassess the field's trajectory and explore strategies to scale RL towards Artificial SuperIntelligence (ASI), despite facing challenges in computational resources and algorithm design.
A prime example cited in the survey is DeepSeek-R1, an open-source reasoning model released in January 2025. DeepSeek-R1 stands out for its development cost, reportedly less than $6 million, directly challenging the notion that advanced AI requires exorbitant investment. This model leverages large-scale RL, innovative rule-based reward engineering, and emergent behavior networks to achieve sophisticated reasoning without traditional supervised fine-tuning.
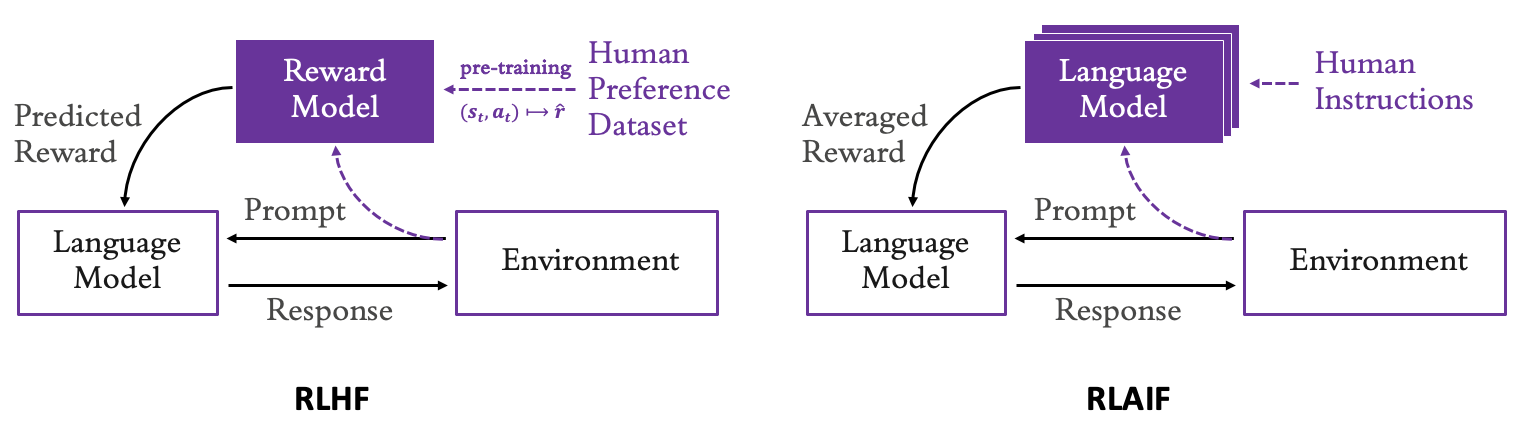
DeepSeek-R1's success demonstrates RL's potential to enable LLMs to decompose complex problems, perform self-reflective reasoning, and engage in multi-step planning, mirroring capabilities seen in models like OpenAI's o1 series. The survey notes that RL techniques, including Reinforcement Learning from Human Feedback (RLHF) and its variants like Direct Preference Optimization (DPO) and Group Relative Policy Optimization (GRPO), are central to aligning and enhancing these models for real-world applications.
The widespread sharing of such research by figures like Rohan Paul, known for his "Rohan's Bytes" newsletter, further amplifies the discussion around these breakthroughs. The survey concludes that continued innovation in RL is crucial for balancing capability enhancement with safety and scalability, paving the way for more efficient and powerful reasoning AI.