Google Research's MedGemma 27B Multimodal Achieves 90.5% on EHR Reasoning, Enhancing Health AI Accessibility
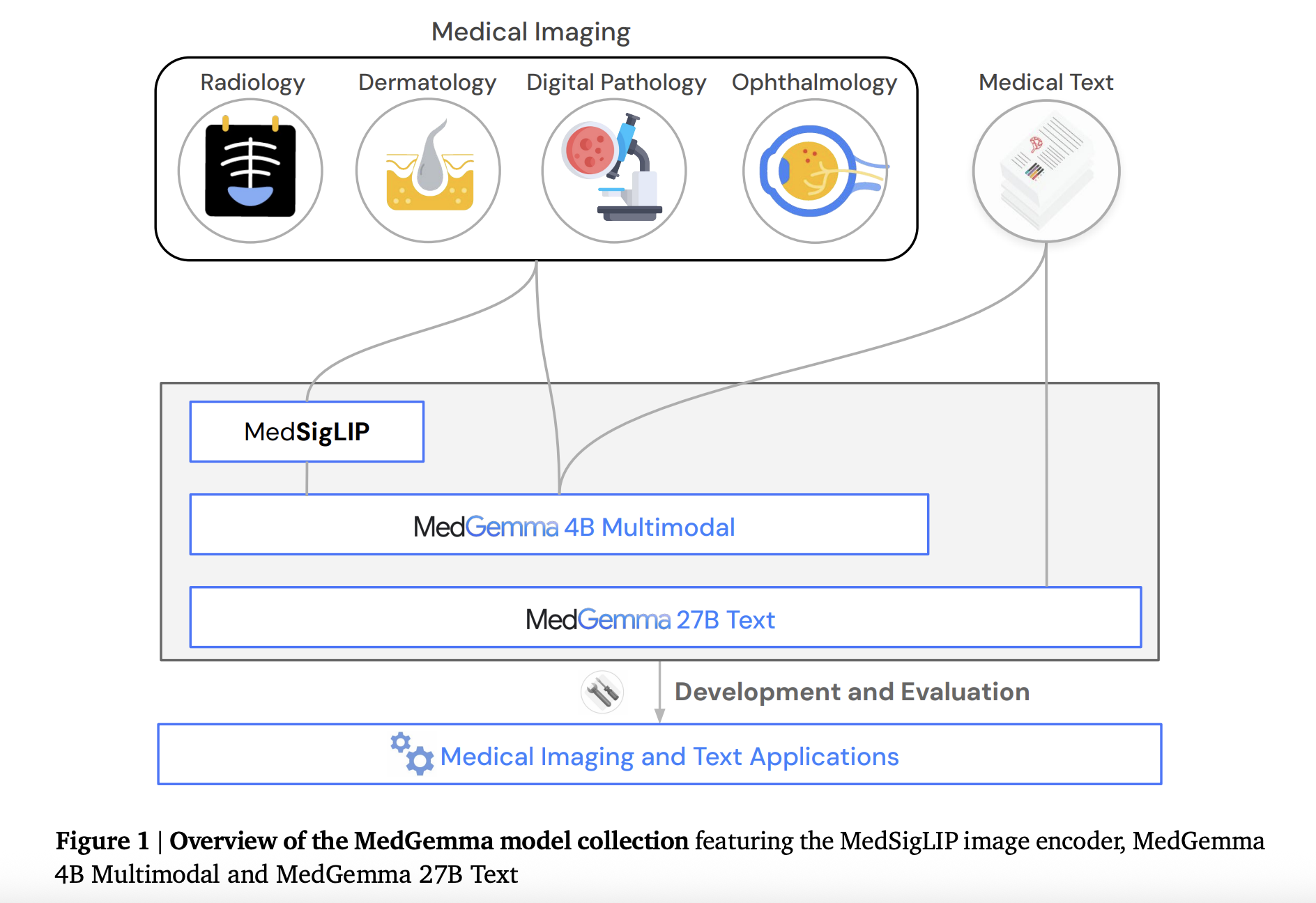
Google Research has announced the release of MedGemma 27B Multimodal, a significant advancement in health AI models designed to accelerate development in healthcare and life sciences. This new model, part of the Health AI Developer Foundations (HAI-DEF) initiative, integrates vision capabilities into a 27-billion-parameter language core, building upon earlier 4B multimodal and 27B text-only variants. The strategic release aims to provide developers with robust, efficient, and privacy-preserving tools for medical AI applications, with the 27B multimodal version achieving a notable 90.5% on the EHRQA benchmark.
The MedGemma 27B Multimodal model expands its predecessors by incorporating vision capabilities, enabling it to interpret complex multimodal data. According to Rohan Paul's tweet, "Training added 2 new datasets, EHRQA and Chest ImaGenome, so the model can read longitudinal electronic health records and localize anatomy in chest X-rays." This enhancement allows the model to reason across both medical scans and textual notes, inheriting the foundational skills of the 4B model while markedly improving language fluency, EHR reasoning, and visual grounding.
Performance benchmarks highlight the capabilities across the MedGemma family. The 4B variant achieves "64.4% MedQA and 81% radiologist-validated X-ray reports," while the 27B text model scores "87.7% at about 10% of DeepSeek R1’s cost." The newly released 27B multimodal model demonstrates superior performance in electronic health record comprehension, scoring 90.5% on the EHRQA dataset, a crucial capability for clinical applications.
A key advantage of the MedGemma models is their accessibility and focus on data privacy. Both the MedGemma and the accompanying MedSigLIP image encoder are designed to "load on a single GPU," with the 4B versions even capable of running on mobile-class hardware. This efficiency lowers deployment costs and facilitates on-premise implementation, which is critical for healthcare institutions dealing with sensitive patient data. The open model approach ensures that "hospitals gain privacy, reproducibility, and full control compared with remote APIs."
MedGemma is built on the Gemma 3 architecture and fuses its language core with the MedSigLIP vision encoder, which unifies radiology, dermatology, and retina images into a shared embedding space. This modular design allows developers to utilize MedSigLIP independently for structured outputs like classification or retrieval, while reserving MedGemma for free-text generation tasks such as report writing or visual question answering. Google Research emphasizes that these models serve as strong starting points, with simple fine-tuning capable of further enhancing performance, as demonstrated by a 4B chest-X-ray RadGraph F1 score of 30.3 after fine-tuning.